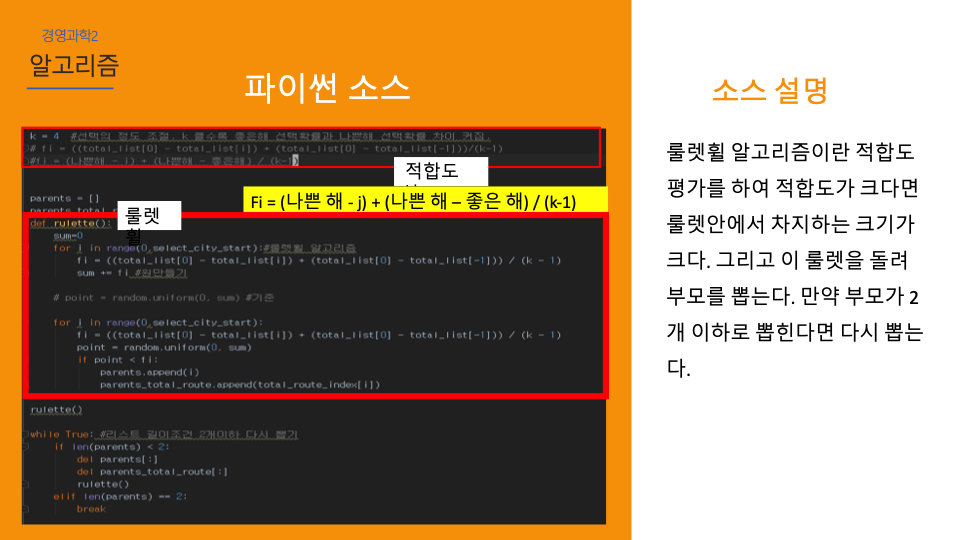
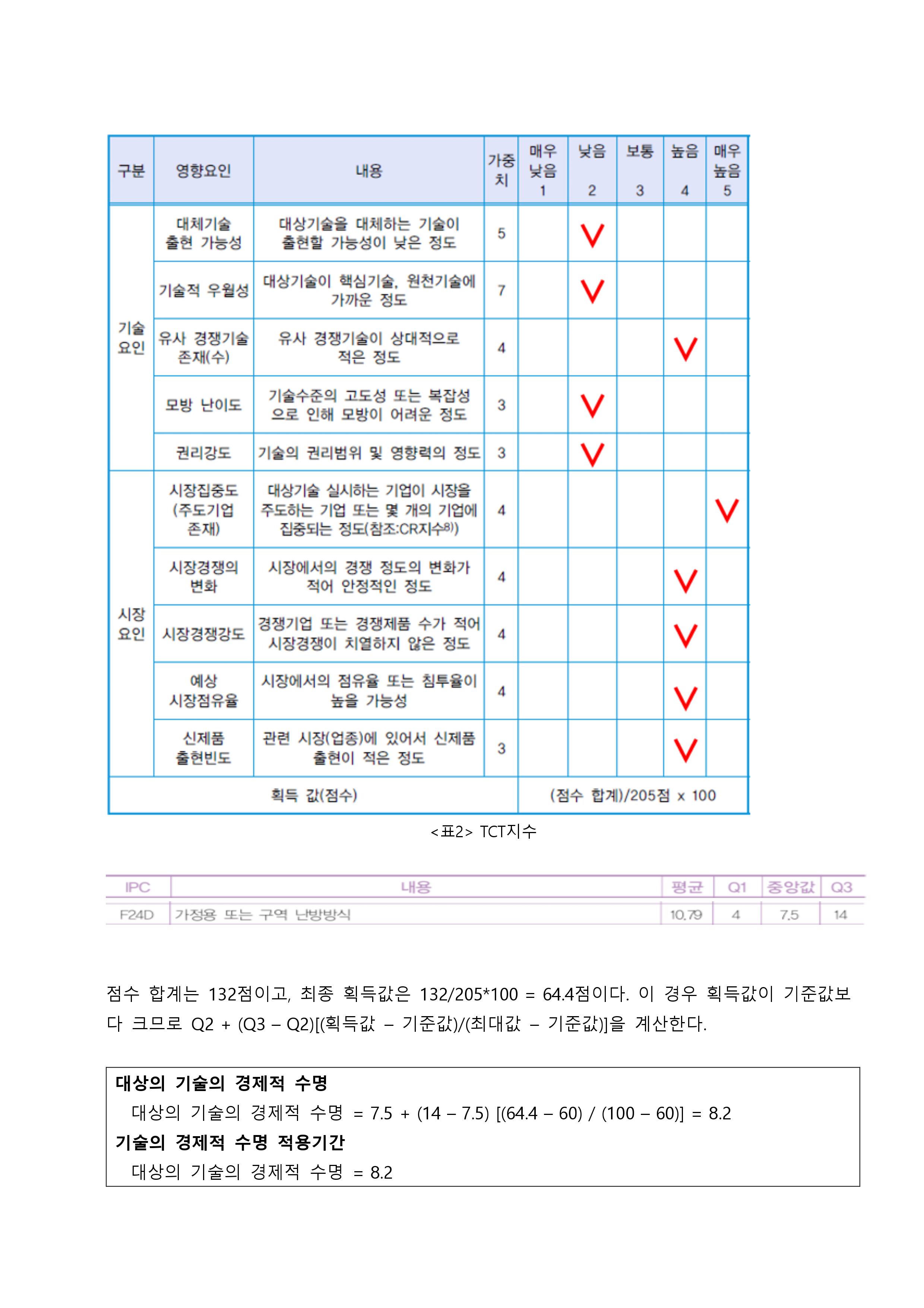
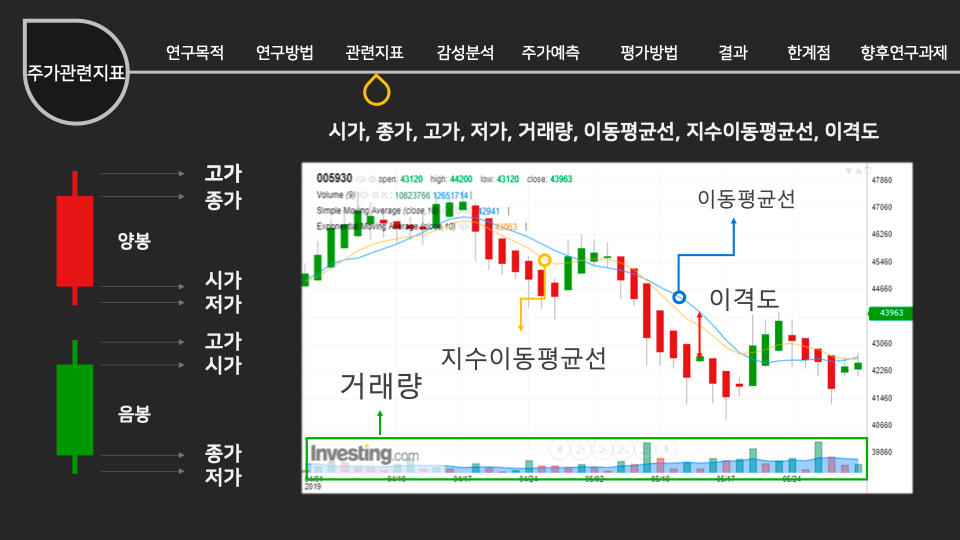
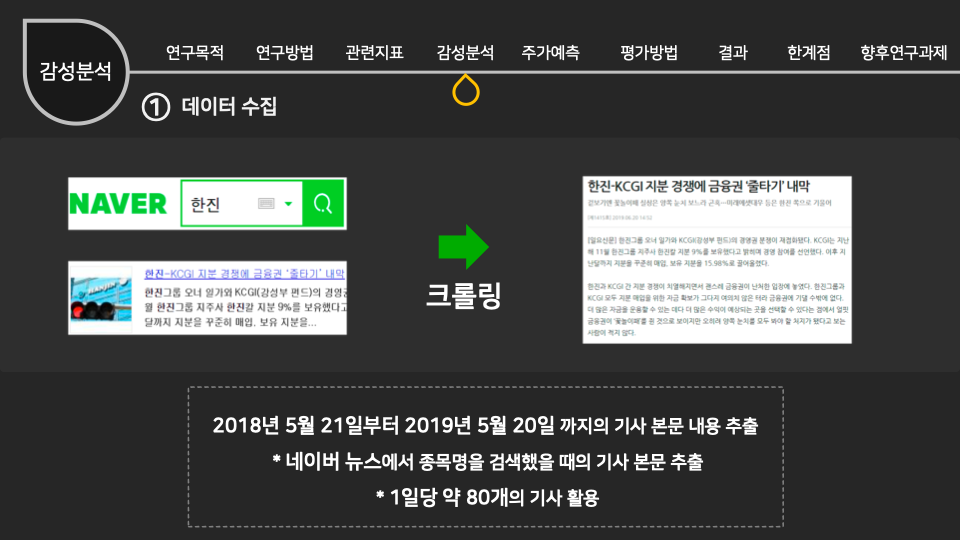
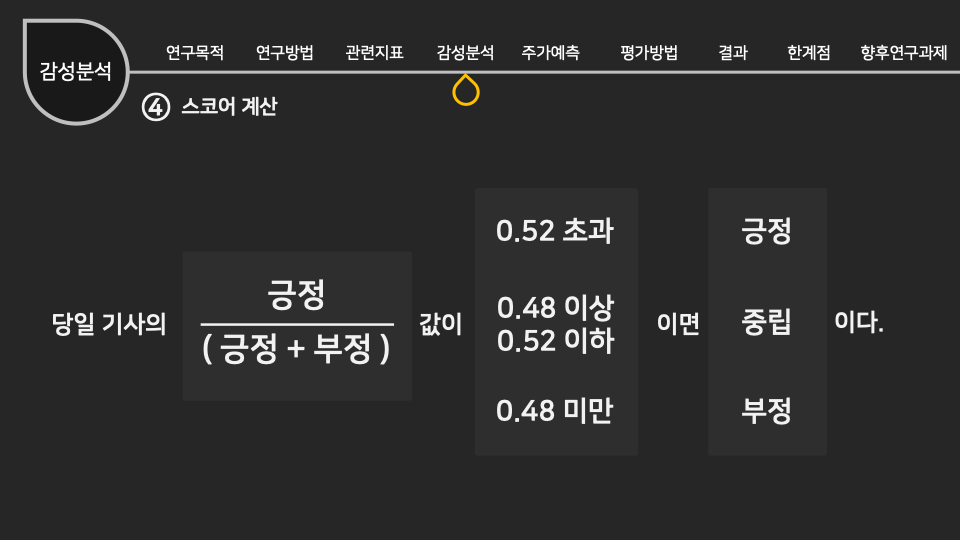
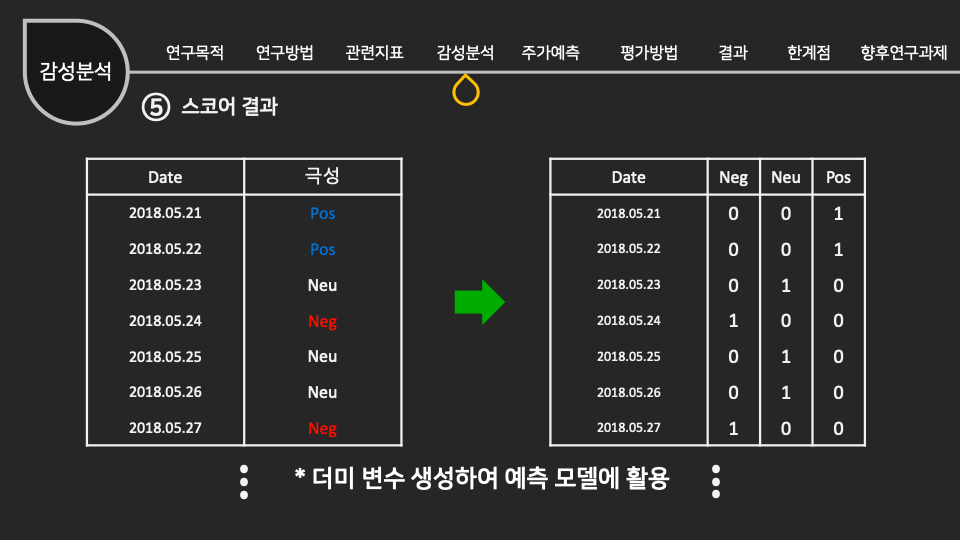
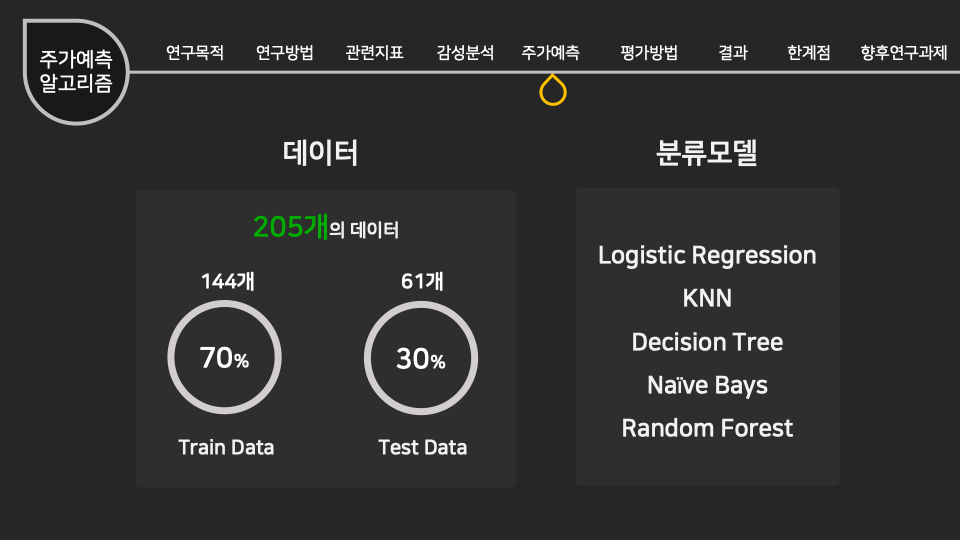
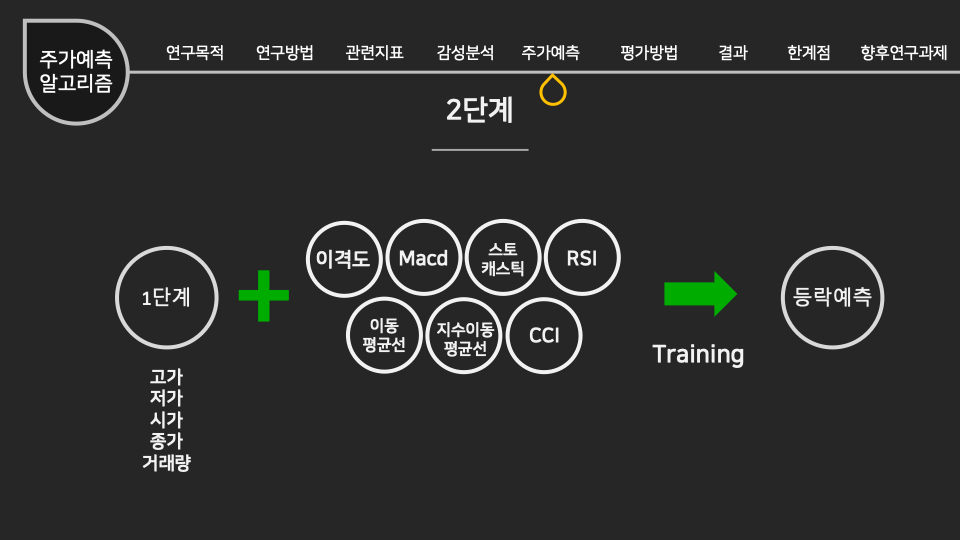
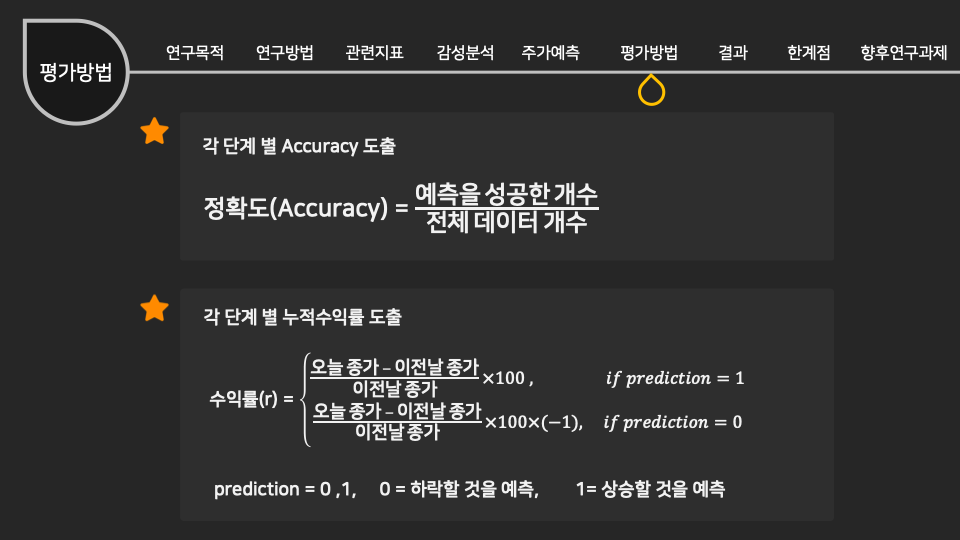
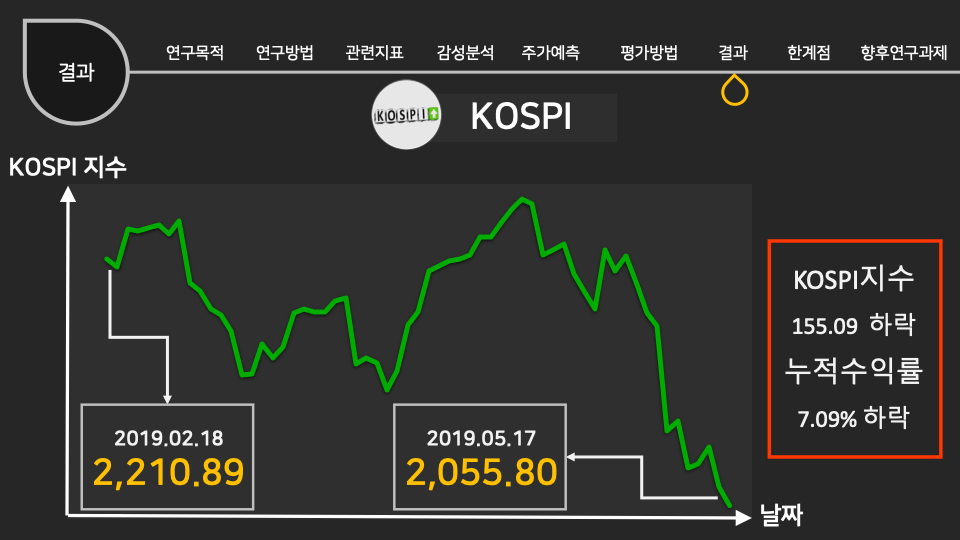
인공지능/자동화/로봇의 전망에 대한 인식조사 설문개요 조사 목적 로봇과 우리사회에 대한 시민들의 인식을 조사하기 위함 조사 배경 공장의 자동화 기계, 인간형 로봇, 알고리즘, 소프트웨어, 기계학습(머신러닝) 등을 통해 전통적으로 사람이 수행하던 일을 자동으로 보완하거나 대체하는 경우가 많아지고 있다. 사람이 수행하던 일을 대체하거나 보완하는 컴퓨터를 비롯한 모든 장치들을 통칭해 ‘로봇’으로 부를 수 있다. 현재 우리가 느끼기엔 IT 기술발전이 중요하다고 생각 되어 지고 있는데, 여러 분야의 일반적인 사람들의 인식은 어떨지 조사하다보니, 주어진 원시데이터로 분석하여 시민들의 평가에 따라 군집을 형성해 각 군집의 특성을 파악 해보고자 한다. 설문 데이터 획득 방법 기관 제공 미디어·시사 이슈 웹매거진 <미디어이슈> 및 자체 연구과제에 활용된 설문조사 원시데이터
군집 분석 군집 분석의 목적 각 문항에 대한 등간척도 응답 결과를 토대로 로봇의 인식에 대한 응답자들을 군집으로 분류하기 위함이다. 분석 과정 척도를 전혀 동의 안함, 동의 안함, 대체로 동의함, 매우 동의함으로 설문조사를 실시한 데이터를 순서대로 최소 1, 최대 4의 척도로 데이터를 입력 하였기에 큰 차이를 보이는 것이 어려워, 점수를 표준화하여 연속적인 데이터로 변환 후 군집분석을 실시함. 각각의 응답자들이 로봇에 대한 인식의 군집이 어떻게 나뉘는지 확인하고자 군집분석을 실시하였고, 데이터가 약 1000개로 크기가 큼에 따라서 K-means clustering을 수행하였다. 반복 횟수는 50회로 설정하였고, 9번째 반복에서 중심 군집이 0으로 수렴하여 완전히 분류되었다. 각 군집의 케이스 수 총 1038개의 응답치 중 군집1에 472개, 군집2에 566개의 개체가 포함 되었다.
<테이블 1>
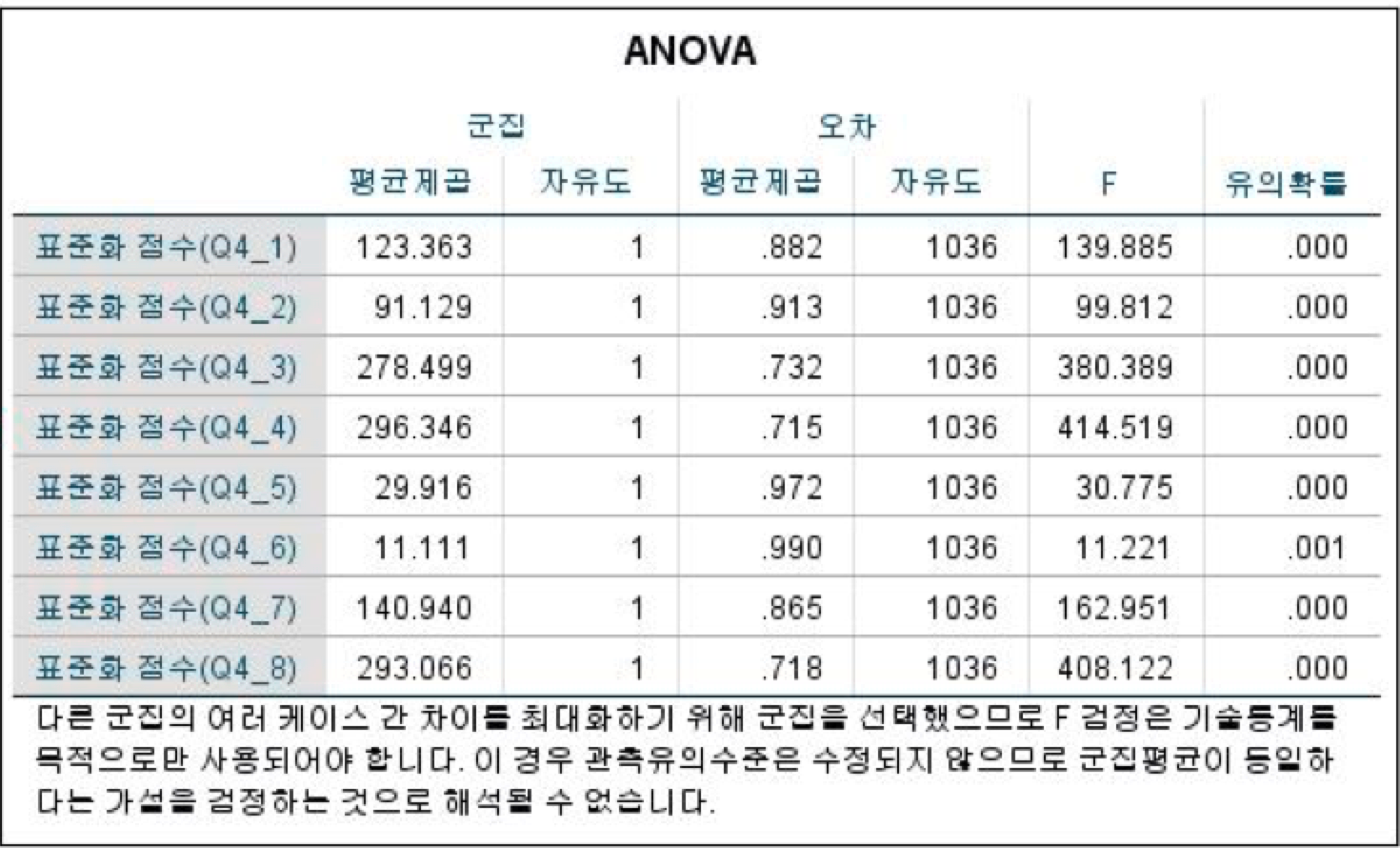
각각의 질문 항목을 표준화한 점수에 대한 분산분석의 결과는 <테이블 2>와 같다. 모든 질문 항목에 대해 유의확률이 매우 작게 나왔다. 따라서 모든 질문 항목들 간에 차이가 존재한다. 다시 말하면 각 설문은 차이가 있는 항목이고 각 설문 항목은 군집을 나누는 기준이 될 수 있다. 따라서 모든 질문 항목에 대한 표준화 점수의 군집중심에 대한 해석을 진행해도 된다.
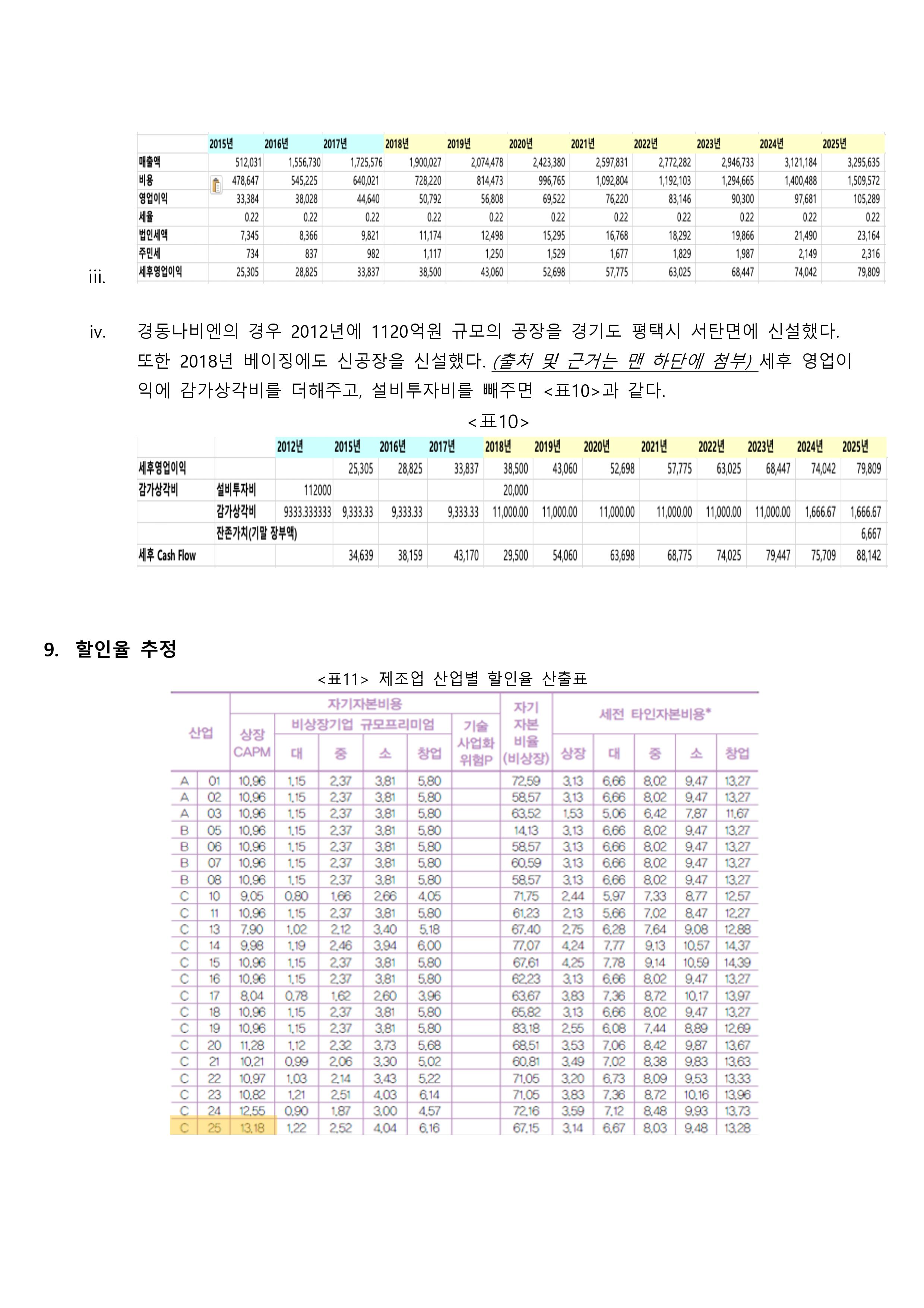
<테이블 2>
군집 중심의 초기 값은 <테이블 3>과 같다.
<테이블 3>
군집 중심의 최종 값은 <테이블 4>와 같다. 군집 1의 경우 1번, 3번, 4번, 5번, 7번, 8번의 질문 항목에 대해 군집 2에 비해 상대적으로 낮은 점수이면서 음의 값을 보인다. 즉, 1, 3, 4, 5, 7, 8번 질문 항목은 상대적으로 낮은 점수를 주었다. 반대로 군집 2의 경우 2, 6번 질문 항목에 대해 낮은 점수인 음수 값을 보이고 있다. 즉 2, 6번 질문에 대해 대체적으로 낮은 점수를 준 군집이다.
<테이블 4>
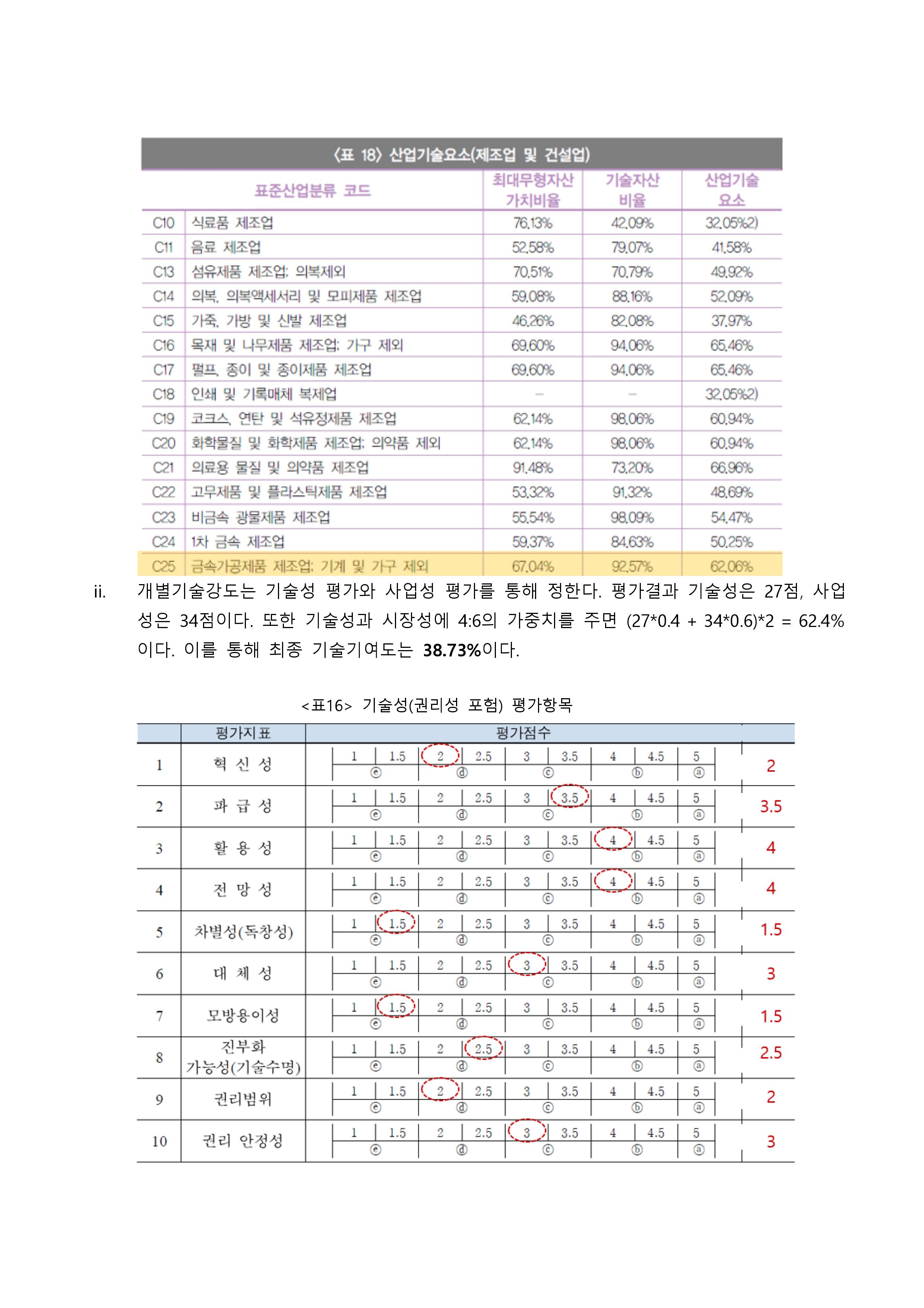
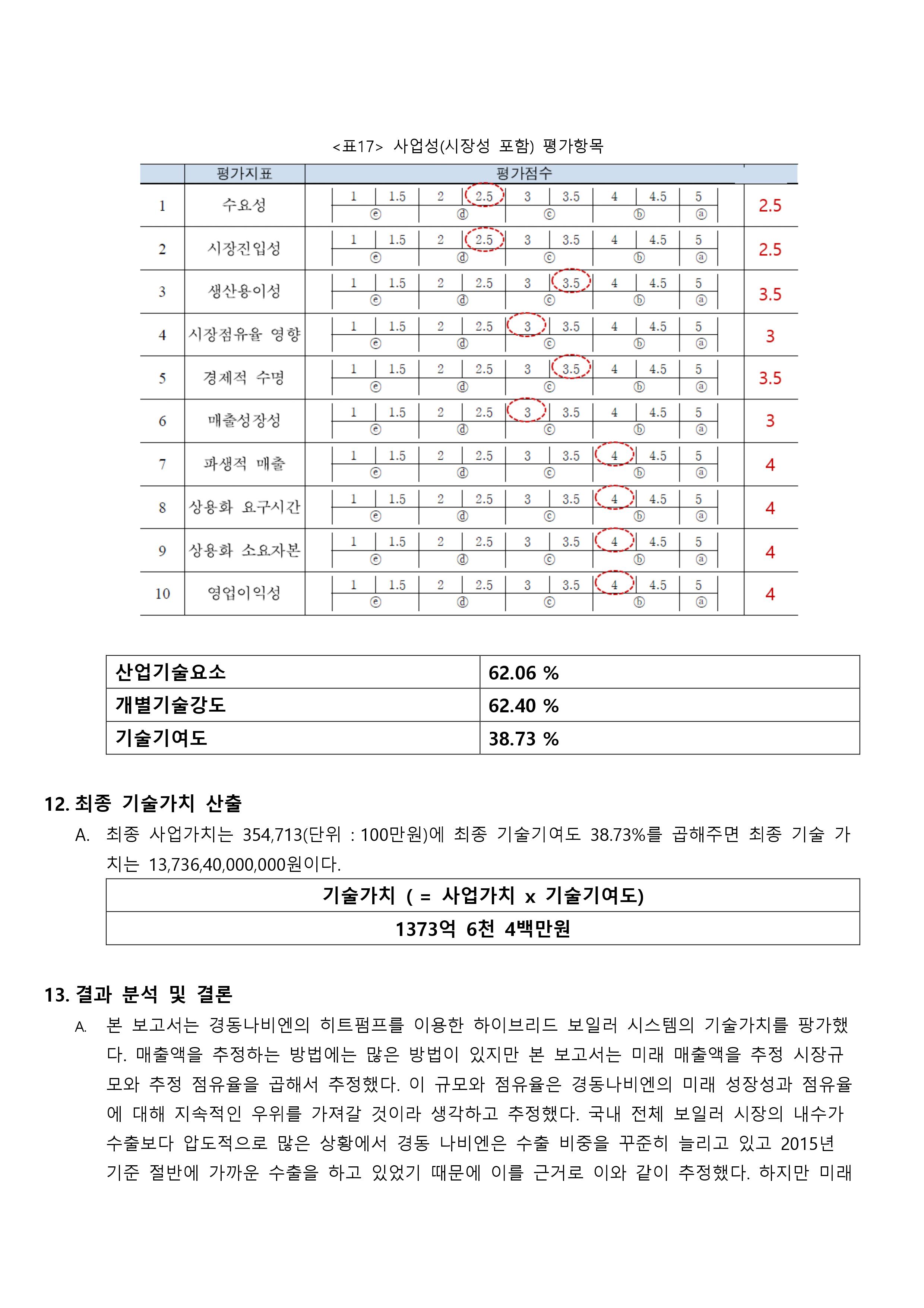
1, 3, 4, 5, 7, 8의 항목의 경우 질문 내용을 보면 기술발전 및 로봇에 대한 긍정적인 내용이다. 이 부분과 앞서 말한 각 군집의 특성의 내용을 종합해보면, 군집 1은 로봇에 대한 긍정적인 질문 내용에 대해 낮은 점수를 부여했다. 즉, 기술발전 및 로봇에 대한 긍정적인 인식이 상대적으로 낮은 군집이라 할 수 있다. 반대로 군집 2는 기술 및 로봇에 대한 부정적인 내용을 가진 2번, 6번 질문 항목에 대해 상대적으로 낮은 점수를 부여한 군집이다. 즉, 기술발전 및 로봇에 대한 부정적인 인식이 낮은 군집이라는 결론을 도출할 수 있다.
결론 군집 1은 군집 2에 비해 인간의 일자리를 빼앗을 것이라는 인식을 가지고 있으며, 군집 2는 군집 1에 비해 기술 발전은 인류에게 혜택을 주면서 기술발전으로 인한 인간의 보다 창조적이고 감성적인 일을 하게 되며, 그만큼 새롭게 생겨날 직업, 일자리도 많을 것이라고 인식을 가지고 있다. 그러나 표준화 한 점수가 아닌 원점수로 군집분석을 했을 때는 기술발전에 대한 로봇의 인식은 대체적으로 두 군집 모두 동의하는 편이며 군집 2가 군집 1에 비해 상대적으로 더 동의하는 군집으로 볼 수 있다.
판별 분석 목적 기존의 설문조사 RAW데이터를 기반으로 판별분석 모델링을 한다. 모델링한 선형함수를 이용해 일반 국민들의 추가적인 설문 내용을 바탕으로 해당 국민이 로봇에 대해 우리가 나눈 군집의 기준으로 어떤 집단에 속하여 인식하는지 구별할 수 있다. 즉 각 질문 항목들을 변수로 활용하여 일반 국민들의 로봇에 대한 인식 성향을 예측하고 판단할 수 있다. R을 통한 분석 과정 > robot = read.csv("인공지능,자동화,로봇에 대한 인식조사.csv") #csv파일 읽어오기 > library(MASS) #판별분석하기 위한 library 등록 > ld=lda(군집~Q4_1 + Q4_2 + Q4_3 + Q4_4 + Q4_5 + Q4_6 + Q4_7 + Q4_8, data=robot) #판별분석 함수 lda(종속변수(집단)~독립변수+독립변수) > set.seed(123) #랜덤함수 고정 > train=sample(nrow(robot),0.7*nrow(robot)) #train data를 쓰기위한 전체데이터중 70%만 추출 > robot.train=robot[train,] #70% train data > robot.test=robot[-train,] #70%외의 test data > ld=lda(군집~Q4_1 + Q4_2 + Q4_3 + Q4_4 + Q4_5 + Q4_6 + Q4_7 + Q4_8, data=robot.train) #train data로 판별분석 실시 – 판별함수 도출 > ld.pred=predict(ld,newdata=robot.test) #predict 함수로 train data로 모델링 한 판별함수에 test data 삽입 후 결과 도출 > ld.pred$class #test data를 모델링 한 판별함수 기준으로 집단 나누기 [1] 2 2 2 1 2 2 2 1 1 1 2 1 2 1 1 2 2 1 2 2 1 1 1 1 1 2 1 1 2 1 1 1 1 2 2 1 2 2 2 2 2 2 2 2 1 1 1 2 1 1 2 [52] 1 1 2 2 2 1 2 1 2 1 2 2 2 1 2 2 2 2 2 1 1 1 2 2 2 2 1 1 2 1 2 1 1 1 1 1 1 1 2 2 1 2 2 2 1 1 2 1 1 2 1 [103] 1 1 2 2 1 1 2 2 2 2 2 2 2 1 1 2 2 2 2 2 2 2 1 2 2 1 2 1 2 2 1 1 1 1 2 2 1 2 1 1 2 2 2 2 2 2 1 1 2 1 1 [154] 2 1 2 1 2 2 1 2 2 1 2 1 2 1 1 1 2 2 1 1 1 1 1 2 2 1 1 1 1 2 1 1 2 2 1 1 2 2 1 2 1 2 2 2 2 1 2 2 2 2 2 [205] 1 2 1 1 1 1 1 1 1 1 2 1 2 1 2 2 1 2 2 2 2 2 1 2 2 2 2 2 1 1 2 1 2 2 1 2 1 2 2 2 1 1 2 1 2 1 2 1 1 1 1 [256] 1 2 2 1 1 2 2 2 1 2 1 1 2 1 2 1 2 2 1 1 2 2 1 1 2 1 1 2 1 1 2 1 2 2 1 1 2 1 2 2 1 1 2 2 1 2 1 2 2 2 1 [307] 2 1 2 2 1 1 Levels: 1 2
> sum(diag(prop.table(t))) #모델링한 판별함수의 Accuracy(hit ratio) 약 98% [1] 0.9871795
상응분석 사전 작업 : 교차분석 교차분석으로 연광성이 있는 것으로 판단되는 변수들 간에 대해서만 상응분석을 실시한다. <테이블 5>는 질문 항목과 SQ1에 대해 교차분석을 한 결과이다. 이렇게 모든 질문에 대하여 SQ1~SQ4, 군집까지 총 질문항목 8개에 대해서 모두 교차분석을 실시한다.
<테이블 5>
교차 분석을 실시한 결과 카이제곱 검정에서 카이제곱의 유의확률을 봤을 때 0.01보다 작으면 유의하다. 즉, 연관성을 가지기 때문에 유의한 질문과의 관계만 뽑아낸다. 결과적으로 각 질문 항목들과의 연관성을 살펴보면, 1번 질문과 성별, 직업, 3번 질문과 직업, 4번 질문과 출생년도, 5번 질문과 직업, 6번 질문과 출생년도, 지역이 각각 연관성이 있다.
상응분석 포지셔닝맵 분석 및 해석 각각의 연관성이 있는 항목별로 다중상응분석을 실시한다. 상응분석을 실시하는 목적으로는 군집의 특성을 조금 더 구체적으로 알아보기 위해, 그 군집에서 나이, 직업, 성별, 지역에 따라 질문에 대해 어떻게 생각 하는 지를 알아보고자 한다.
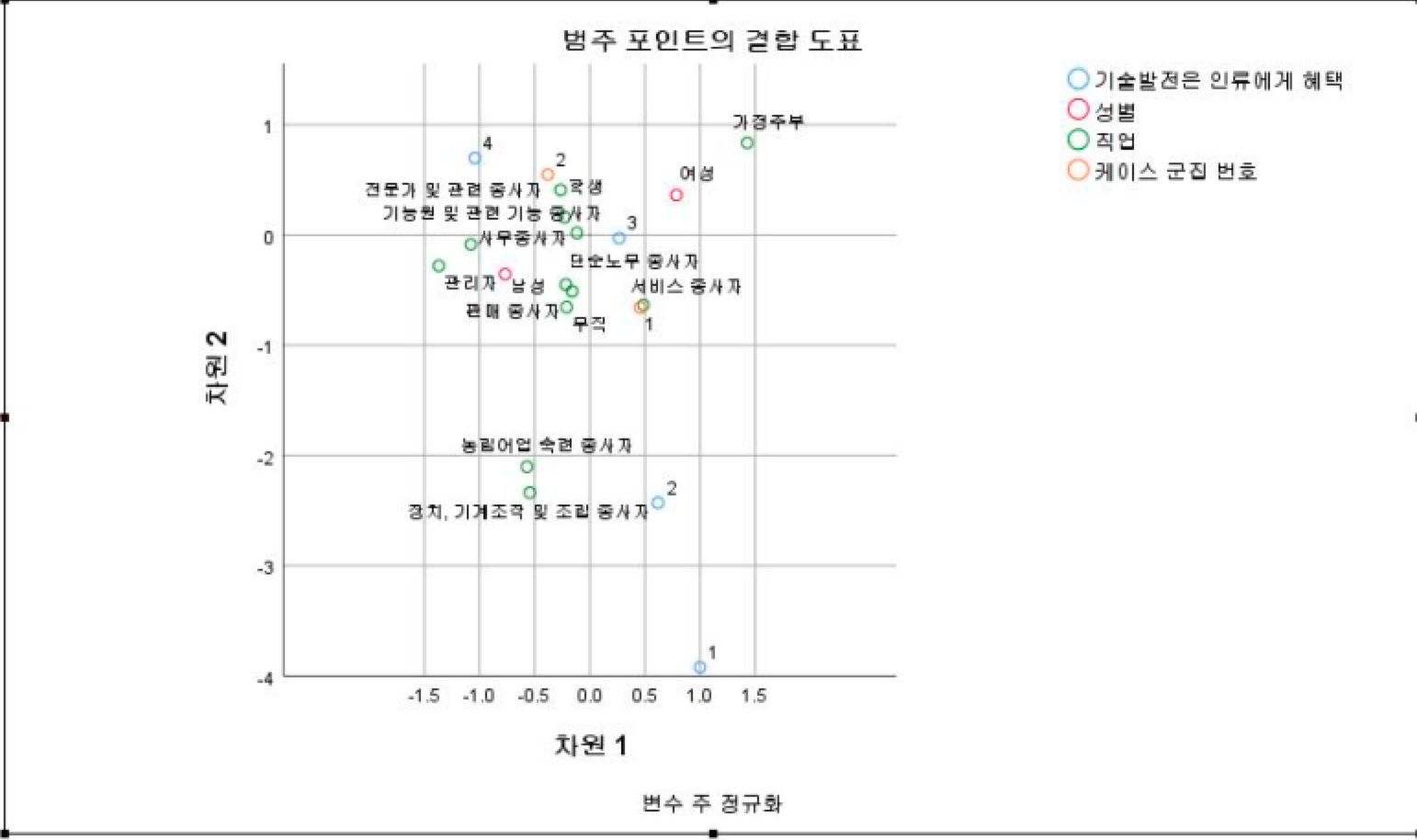
<테이블6>
<테이블 6>은 1번 ‘기술발전은 인류에게 혜택을 줄 것인가’에 대한 질문과 연관성 있는 성별, 직업, 군집에 대한 상응분석 결과(포지셔닝 맵)이다. 이 포지셔닝 맵으로 미루어보면 성별과 직업에 따라서 대체로 동의하는 편이며, 그중 관련 종사자들은 매우 동의하는 편이다. 반대로 농림어업 숙련 종사자, 장치/기계 조작 및 조립 종사자는 동의하지 않는 편이다.
<테이블7>
<테이블 7>은 ‘사람이 하는 일을 대체해 사람들은 자유롭게 여가생활을 즐길 수 있다’라는 3번 질문과 연관성 있는 직업에 대한 상응분석 결과(포지셔닝 맵)이다. 대부분의 사람들은 중립적인 의견을 보이나 미세하게 대체로 동의하는 쪽에 가깝게 매핑되었다. 로봇 덕분에 여가생활을 즐길 수 있다는 것에 대해 극단적으로 동의하거나 동의하지 않는 의견은 거의 보이지 않는다. 무직과, 관련종사자 사람들이 3번 질문에 대한 포지셔닝이 어느 점수에도 가깝지 않고 어중간한 중간 위치에 위치해있다. 무직자 및 관련 기능종사자라는 직업군은 이 질문에 대해 다양한 의견이 나온 집단이라 할 수 있다. 즉, 이 직업군은 이 질문에 대해 뚜렷한 특성을 나타내지 않는다.
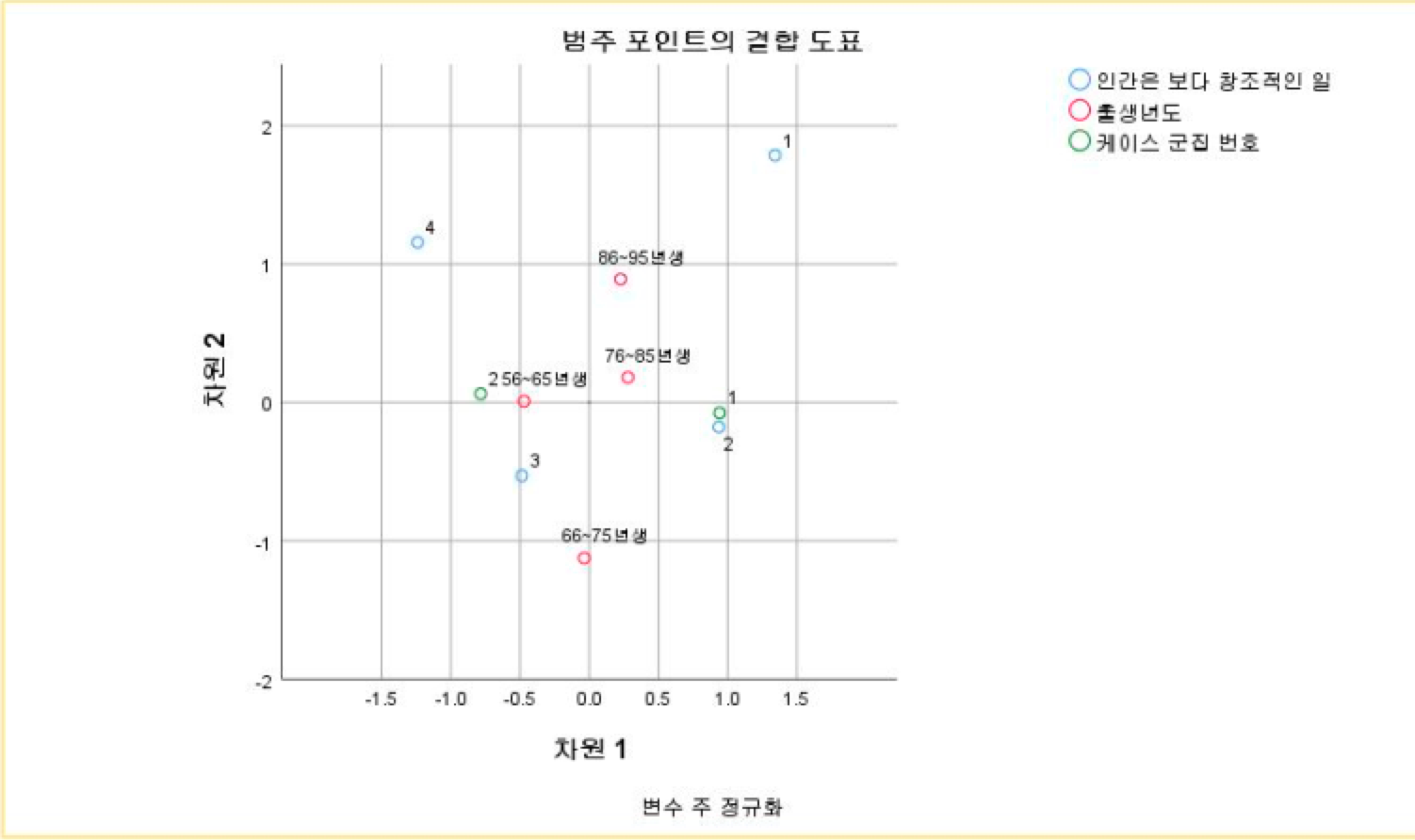
<테이블 8>
<테이블 8>은 ‘인간은 보다 창조적인 일을 담당하게 될 것이다’라는 4번 질문과 연관성 있는 출생년도에 대한 상응분석 결과(포지셔닝 맵)이다. 1번 군집의 대부분 사람들이 이 질문에 대해 동의하지 않는다고 응답한 것을 알 수 있다. 86~95년생 그룹과 76~85년생 그룹의 경우 평가점수 4곳의 중간쯤 어중간하게 포지셔닝된 것으로 보아 이 그룹들도 다양한 답변이 나온 것으로 판단된다. 즉 86~95년생, 76~85년생 그룹은 이 질문에 대한 특성과 연관성을 뚜렷하게 보이지 않는 그룹이다. 그러나 56~65년생 그룹과 66~75년생 그룹의 경우 상대적으로 3번 응답에 가까운 것으로 나타난다. 즉, 이 연령대의 응답자들은 대체적으로 이 질문에 대해 긍정적인 답변을 했다고 할 수 있다.
<테이블 9>
<테이블 9>는 ‘인간의 감성, 창의력, 비판력이 요구되는 일/직업은 대체되기 어려울 것이다.’라는 질문과 연관성 있는 직업에 대한 상응분석 결과(포지셔닝 맵)이다. 이 포지셔닝 맵으로 미루어보면 전체적으로 전혀 동의하지 않는 사람들은 없으며, 대부분의 직업군이 대체로 동의하다는 응답과 대체로 동의하지 않는다는 응답을 골고루 한 것으로 보인다. 관련 종사자 들은 로봇이 인간의 감성을 대체하는 일은 하기 쉽지 않을 것이라는 질문에 매우 동의한다.
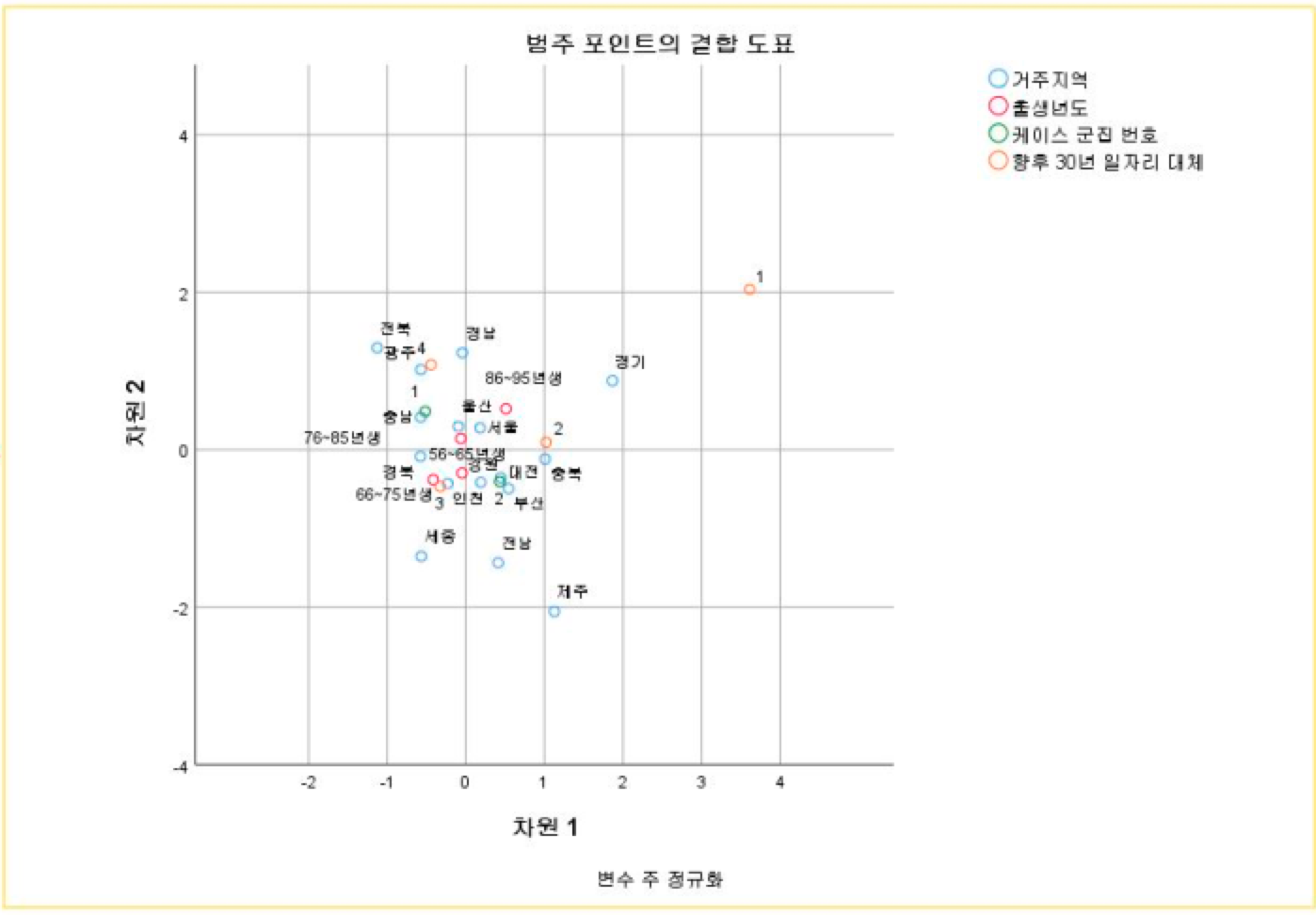
<테이블 10>
<테이블 10>은 ‘향후 30년 내 현재 사람 일자리의 50%를 대체할 것이다.’라는 6번 질문과 연관성 있는 거주 지역, 출생년도대한 상응분석 결과(포지셔닝 맵)이다. 이 질문에 대해 전혀 동의하지 않는 다는 생각을 한 사람들은 거의 없는 것으로 보인다. 다만 경기 지역 사람들의 경우 대체적으로 이 질문에 동의하지 않는다는 응답을 많이 한 것으로 보인다. 전북, 광주, 경남, 충남 지역의 경우 이 질문에 대해 매우 동의하고 있다. 이외의 지역은 다양한 응답이 섞여 나온 것으로 보이며 뚜렷한 구분이 없어 보인다.
상응분석 결론 종합 각각의 상응분석 포지셔닝 맵에서 군집분석에서 나왔던 결론처럼 대체적으로 1번 군집과 2번 군집의 큰 차이는 없으나 상대적으로 로봇에 대한 긍정적인 질문에 대해서는 1번은 상대적으로 낮은 점수에 근접하며, 2번 군집은 부정적인 질문에 상대적으로 낮은 점수에 근접하다. 교차분석을 실시하였을 때 연관성 있는 항목으로 5개의 질문이 분류 되었고 인구특성은 대체로 오밀조밀하게 모여 있어 해석하기 어렵다. 그러나 직업에 대해서는 연관성이 있어 보인다. 특히 1번 ‘기술발전은 인류에게 혜택을 줄 것인가’에 대한 질문과 5번 ‘인간의 감성, 창의력, 비판력이 요구되는 일/직업은 대체되기 어려울 것이다.’라는 질문에서 관련 종사자들은 매우 동의한다는 뚜렷한 의견으로 응답했다.